| Ⅰ | This article along with all titles and tags are the original content of AppNee. All rights reserved. To repost or reproduce, you must add an explicit footnote along with the URL to this article! |
| Ⅱ | Any manual or automated whole-website collecting/crawling behaviors are strictly prohibited. |
| Ⅲ | Any resources shared on AppNee are limited to personal study and research only, any form of commercial behaviors are strictly prohibited. Otherwise, you may receive a variety of copyright complaints and have to deal with them by yourself. |
| Ⅳ | Before using (especially downloading) any resources shared by AppNee, please first go to read our F.A.Q. page more or less. Otherwise, please bear all the consequences by yourself. |
| This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. |
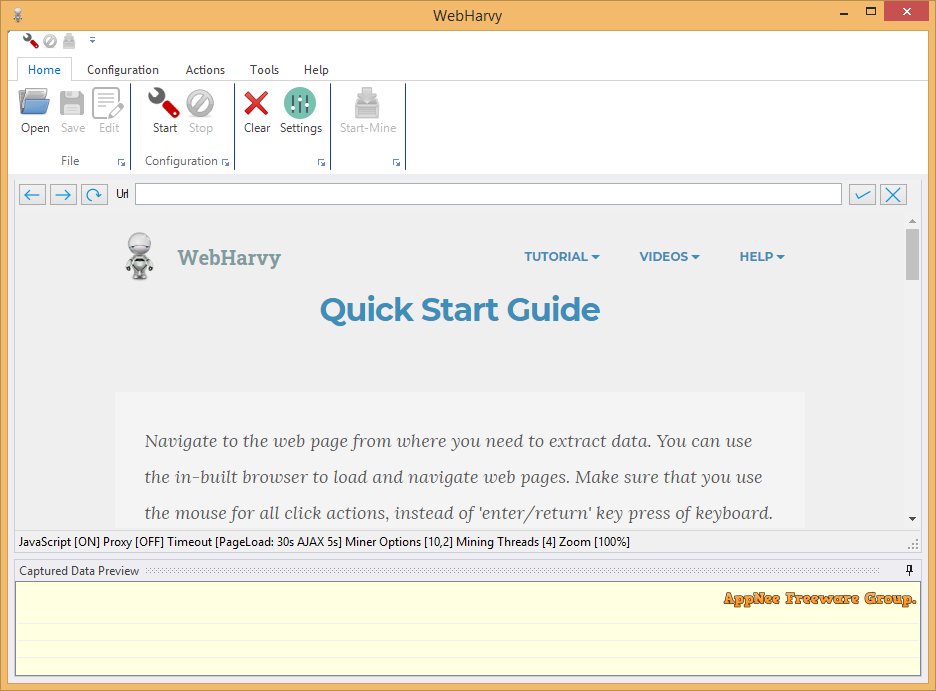
WebHarvy is a powerful, professional and visual web data collection tool specially made for non-program developers, developed by SysNucleus from India. It has simple and clear user interface and intelligent operation mode, and is very easy to use. User simply enters the URL address of a target website in its built-in browser, and there is no need to write any scripts or code to grab the web data with ease. In theory, any data that can be seen on a web page can be collected with reasonable configuration in WebHarvy.
WebHarvy is able to automatically grab text, images, URLs, E-mail addresses and other contents from websites, and export the captured data into a variety of common file formats or database, such as XML, CSV, JSON, TSV, SQL. In addition, it can apply regular expressions to pure text or the HTML source code of a web page to accurately extract the required parts. This powerful technology does provide greater flexibility when grabbing the web data.
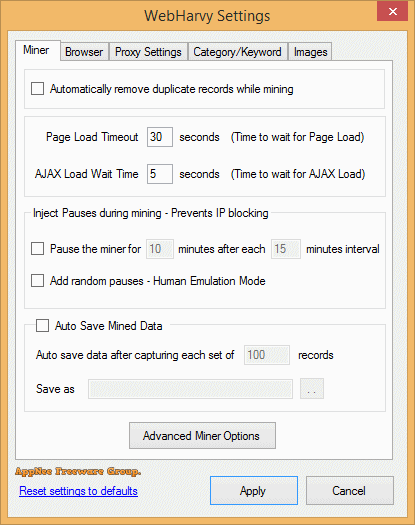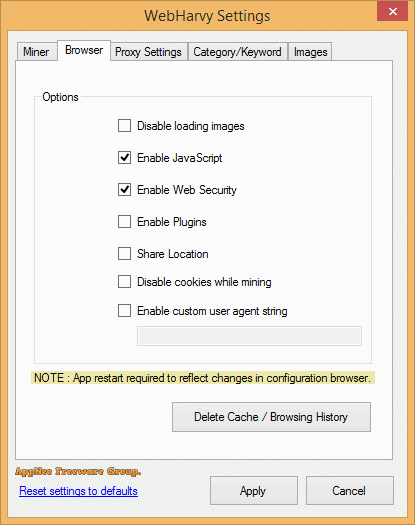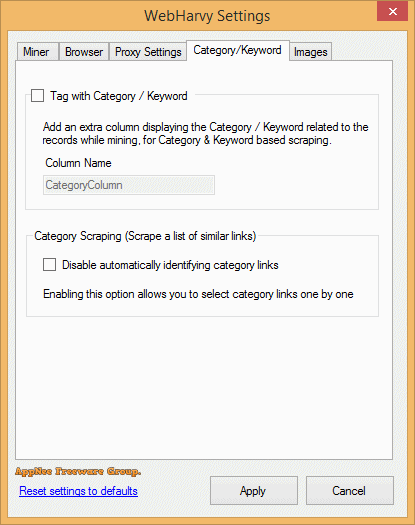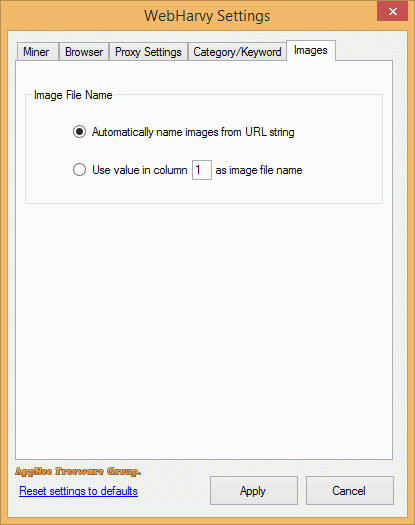
WebHarvy automatically detects and identifies the data patterns used by web pages (including data protection modes); supports external links analysis, keywords extraction, automatic deletion of duplicate data; automatically gets the list of all relevant links, etc. As a result, you only need to copy one URL address to start to search and collect content from multiple web pages! Plus, it also provides scheduler and proxy supports. With proxies, users can crawl websites anonymously and prevent themselves from being blocked by Web servers.
// Key Features //
| Easy Web Scraping |
| Web Scraping is easy with WebHarvy’s point and click interface. There is absolutely no need to write any code or scripts to scrape data. You will be using WebHarvy’s inbuilt browser to load websites and you can select the data to be extracted with mouse clicks. It is that easy! |
| Intelligent pattern detection |
| WebHarvy automatically identifies patterns of data occurring in web pages. So if you need to scrape a list of items (name, address, email, price etc.) from a web page, you need not do any additional configuration. If data repeats, WebHarvy will scrape it automatically. |
| Save to file or database |
| You can save the data extracted from websites in a variety of formats. The current version of WebHarvy Web Scraping Software allows you to save the extracted data as an Excel, XML, CSV, JSON or TSV file. You can also export the scraped data to an SQL database. |
| Crawl multiple pages |
| Often websites display data such as product listings or search results in multiple pages. WebHarvy can automatically crawl and extract data from multiple pages. Just point out the ‘link to load the next page’ and WebHarvy Web Scraper will automatically scrape data from all pages. |
| Submit Keywords |
| Scrape data by automatically submitting a list of input keywords to search forms. Any number of input keywords can be submitted to multiple input text fields to perform search. Data from search results for all combinations of input keywords can be extracted. |
| Safeguard Privacy |
| To scrape anonymously and to prevent the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers or VPN. Either a single proxy server address or a list of proxy server addresses may be used. |
| Category Scraping |
| WebHarvy Web Scraper allows you to scrape data from a list of links which leads to similar pages/listings within a website. This allows you to scrape categories and subcategories within websites using a single configuration. |
| Regular Expressions |
| WebHarvy allows you to apply Regular Expressions (RegEx) on Text or HTML source of web pages and scrape the matching portion. This powerful technique offers you more flexibility while scraping data. |
| JavaScript Support |
| Run your own JavaScript code in browser before extracting data. This can be used to interact with page elements, modify DOM or invoke JavaScript functions already implemented in target page. |
| Image Extraction |
| Images can be downloaded or image URLs can be extracted. WebHarvy can automatically extract multiple images displayed in product details pages of eCommerce websites. |
| Automate browser tasks |
| WebHarvy can be easily configured to perform tasks like Clicking Links, Selecting List/Drop-down Options, Input Text to a field, Scrolling page, Opening Popups etc. |
// Official Demo Video //
// System Requirements //
- Microsoft .NET Framework 4.7
// Edition Statement //
AppNee provides the WebHarvy multilingual full installers and unlocked files, as well as portable full registered versions for Windows 32-bit & 64-bit.
// Related Links //
// Download URLs //
| Version | Download | Size |
| v7.2.0 |  |
128 MB |
(Homepage)
| If some download link is missing, and you do need it, just please send an email (along with post link and missing link) to remind us to reupload the missing file for you. And, give us some time to respond. | |
| If there is a password for an archive, it should be "appnee.com". | |
| Most of the reserved downloads (including the 32-bit version) can be requested to reupload via email. |